Projects
Overview
Research Interests
I am interested in many different aspects of Computer Vision:
- Large-scale representation learning of 3D Point Cloud
- Instance Segmentation and Object Detection of 3D Point Cloud
- Generative model in video (Frame Prediction and Interpolation).
- Representation learning and feature disentanglement
- Statistical Learning
Current Projects
Object Detection in Point Cloud
Previous Projects
3D Reconstruction from a Single Image
High quality single view 3D reconstruction by using implicit function and local features. Please refer to our publication
[project site]

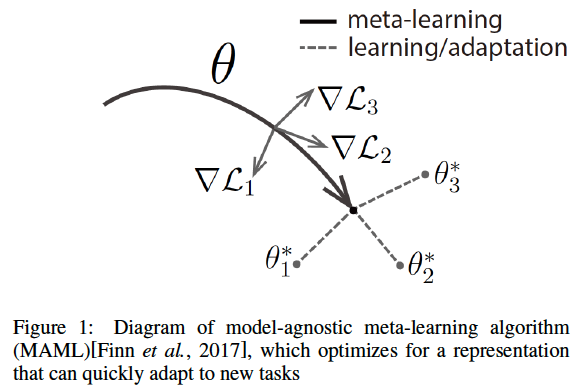
Fast Adaptive Meta-Learning based branching for Mixed Interger Programming
We propose a meta-learning framework for variable selection in the branch-and-bound algorithm of Mixed Integer Programming(MIP). With the meta-learning methodology, we train our base model with samples from various MIP problems to mimic the general variable selection behavior of Strong Branching (SB). At the same time, the base model can also adaptively mimic the behavior of SB for a specific MIP instance, and easily get updated based on the current state once for a while during the branch-and-bound search. Experiments on benchmark instances indicate that our model is able to produce more accurate variable ranking than the state-of-the-art method using SVM ranking[Khalil et al., 2016], even trained with fewer online training sample.
| MAML | Initial Result |
|---|---|
 |
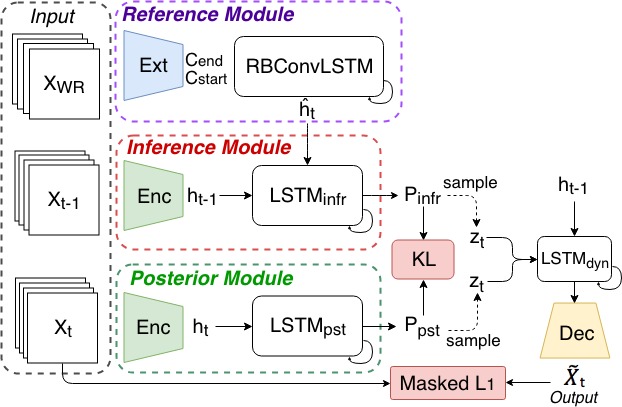
Stochastic Dynamics for Video Infilling [paper] [project site]
We introduce a stochastic generation framework (SDVI) to infill long intervals in video sequences. SDVI consists of two parts: (1) a bi-directional constraint propagation to guarantee the spatial-temporal coherency among frames, (2) a stochastic sampling process to generate dynamics from the inferred distributions. Experimental results show that SDVI can generate clear and varied sequences.
| Motivation | Model |
|---|---|
 |
 |
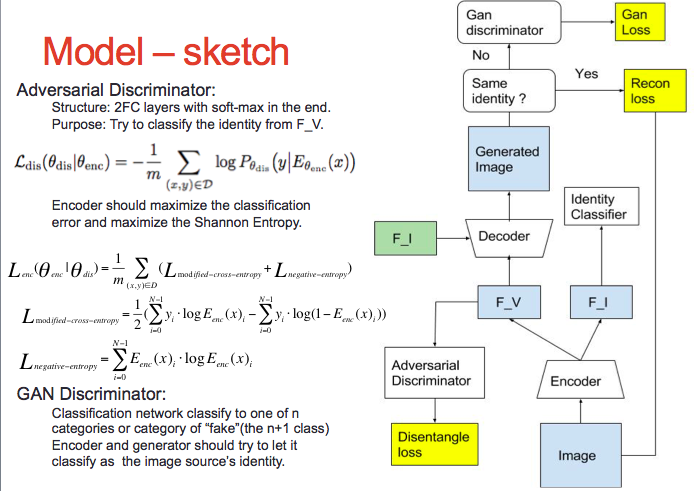
Variation Disentanglement Siamese Net [project site] [code]
A project to study unsupervised disintanglement of image representation: Supervised by Prof. Shih-Fu Chang:
- Designed a semi-supervised network that disentangles the label-related and variance representation of a manifold.
- Introduced a Shannon-Entropy based adversarial training counterpart to help the disentanglement, expelling any label-related information from the variance representation.
- Setting recognition and reconstruction task to keep the richness in the feature embedding.
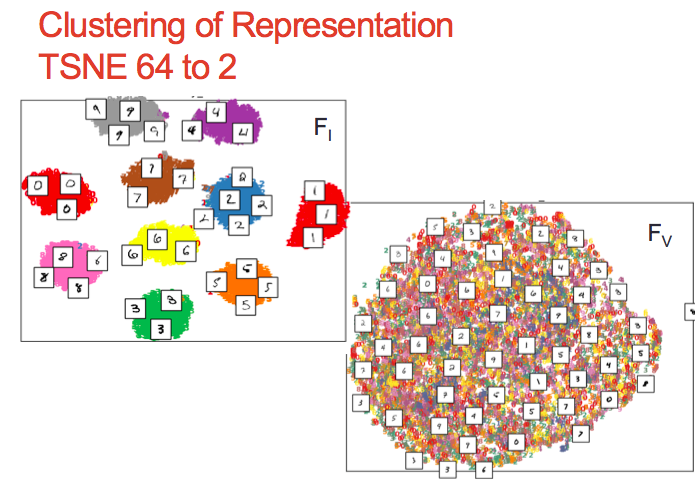
- Implemented the proposed network and conducted the experiment on both MNIST and CASIA Face dataset. Conducted disentanglement, reconstruction, cross-stich evaluation and TSNE Clustering on learnt representation.
| Model | Feature space interpolation | Feature space clustering |
|---|---|---|
 |
 |
 |
Neural Gesture (Funded by NSF) [paper] [code]
The project is leaded by Prof. John Kender, studying relationship between gestures of speakers and audiences’ attention. I have:
- Design and implemented distance matching algorithm based on “Time Warp Edit Distance” between every pair of eye tracking trajectories to get a eye-tracking distance matrix.
- Fine-tuned the hyper-parameter of TWED based algorithm by comparing eye movement trails.
- Clustered subjects based on “fast multi-scale detection of relevant communities” by using the distance matrix.
| Attention fixation | Eye trajectory and co-relation |
|---|---|
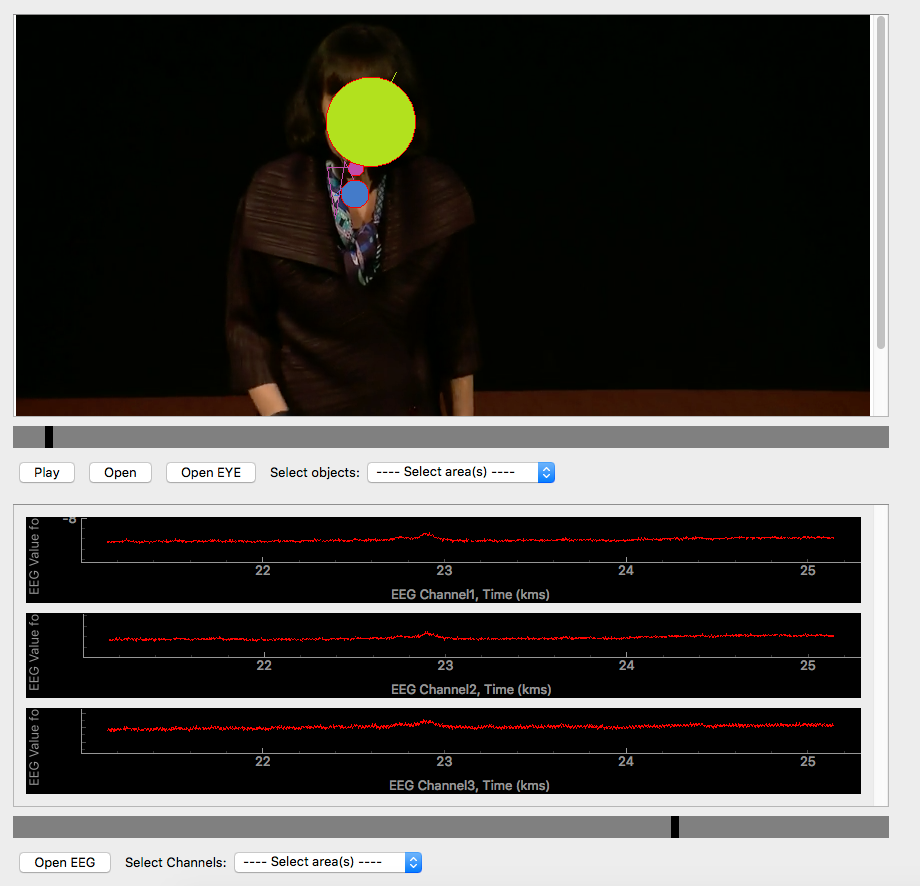 |
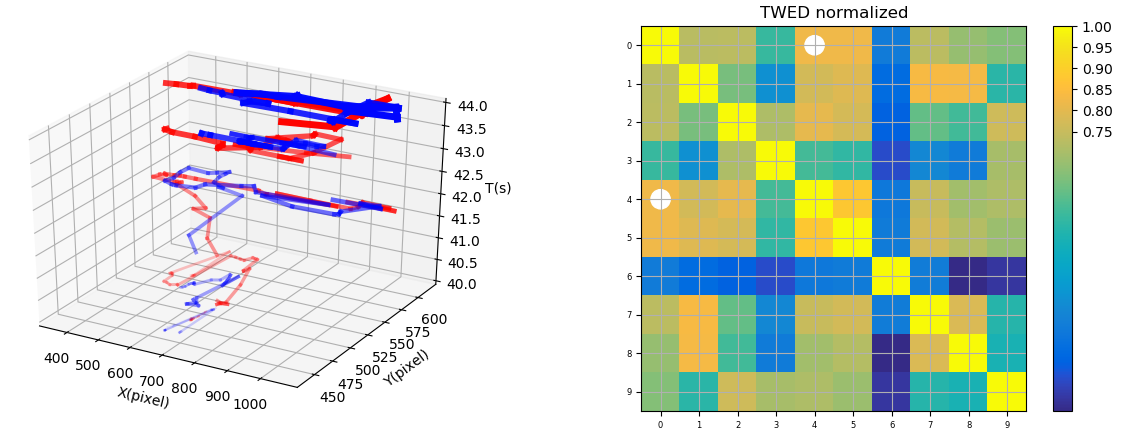 |