Oral Presentation @ CVPR 2022
Abstract
Volumetric neural rendering methods like NeRF generate high-quality view synthesis results but are optimized per-scene leading to prohibitive reconstruction time. On the other hand, deep multi-view stereo methods can quickly reconstruct scene geometry via direct network inference. Point-NeRF combines the advantages of these two approaches by using neural 3D point clouds, with associated neural features, to model a radiance field. Point-NeRF can be rendered efficiently by aggregating neural point features near scene surfaces, in a ray marching-based rendering pipeline. Moreover, Point-NeRF can be initialized via direct inference of a pre-trained deep network to produce a neural point cloud; this point cloud can be finetuned to surpass the visual quality of NeRF with 30X faster training time. Point-NeRF can be combined with other 3D reconstruction methods and handles the errors and outliers in such methods via a novel pruning and growing mechanism.
Pipeline
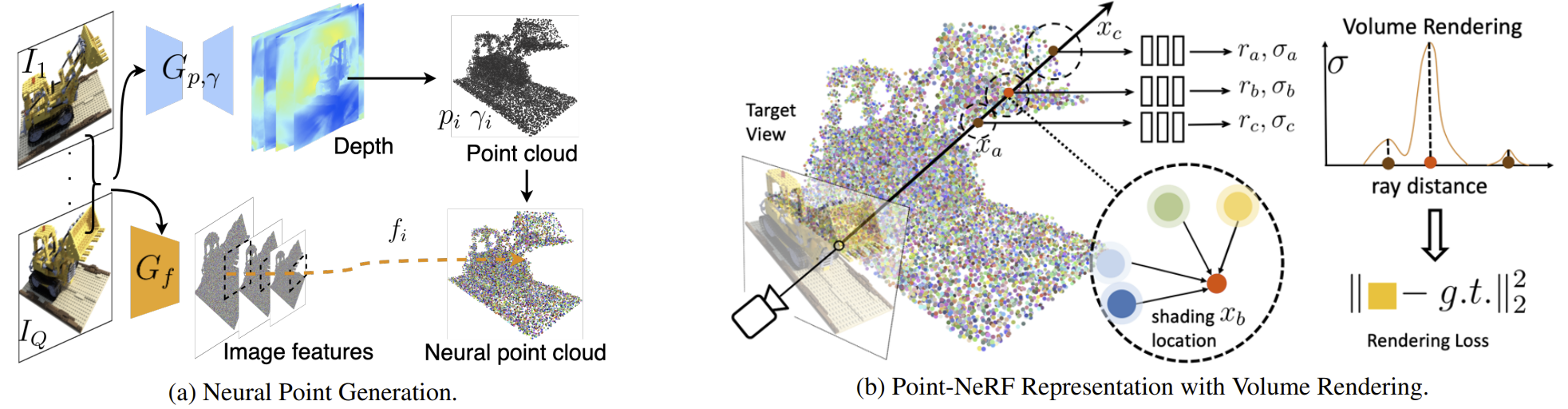
Overview of Point-NeRF. (a) From multi-view images, our model generates depth for each view by using a cost volume-based 3D CNNs and extract 2D features from the input images by a 2D CNN. After aggregating the depth map, we obtain a point-based radiance field in which each point has a spatial location, a confidence and the unprojected image features. (b) To synthesize a novel view, we conduct differentiable ray marching and compute shading only nearby the neural point cloud (e.g., Xa, Xb, Xc). At each shading location, Point-NeRF aggregates features from its K neural point neighbors and compute radiance and volume density then accumulate radiance using density. The entire process is end-to-end trainable and the point-based radiance field can be optimized with the rendering loss..
DTU

NeRF Synthetic

Optimize for 300K steps
Optimize for 20K steps
ScanNet
Scene 101
Scene 241
Tanks and Temples
Family Scene
Truck Scene
Point Growing
Progressively Optimize the inital COLMAP Points
Grow Out the Complete Point Cloud from 1000 Points
Paper